Motivation
The challenges involved in operationalizing machine learning models are one of the main reasons why many machine learning projects never make it to production. The process involves automating and orchestrating multiple steps which run on heterogeneous infrastructure - different compute environments, data processing platforms, ML frameworks, notebooks, containers and monitoring tools. There are no mature standards for this workflow, and most organizations do not have the experience to build it in-house. In the best case, dev-ds-devops teams form in order to accomplish this task together; in many cases, it's the data scientists who try to deal with this themselves without the knowledge or the inclination to become infrastructure experts. As a result, many projects never make it through the cycle. Those who do suffer from a very long lead time from a successful experiment to an operational, refreshable, deployed and monitored model in production.
Apache Liminal was created to enable scalability in ML efforts and after a thorough review of available solutions and frameworks, which did not meet our main KPIs. Few Commercial & Open-source solutions have started to emerge in the last few years, however, they are limited to specific parts of the workflow, such as Databricks MLFlow or tied to a specific environment (e.g. SageMaker on AWS) or a specific tech stack (e.g. KubeFlow).
Liminal Workflows
Apache Liminal provides declarative building blocks which define the workflow, orchestrate the underlying infrastructure and takes care of non functional concerns; thus enabling focus in business logic / algorithm code. Liminal approach is to wrap existing frameworks and libraries with a DSL (Domain-Specific-Language), which is used by data engineers & scientists to express ML/AI workflows using the right abstractions; from model training to real time inference in production.
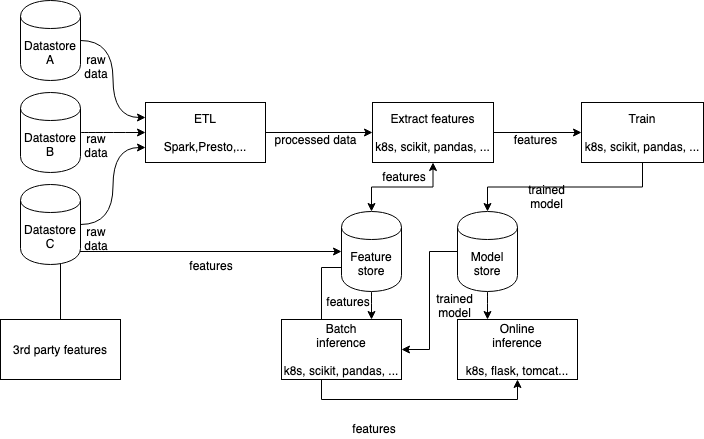
The architecture enables and promotes adoption of specific components in existing (non-Liminal) frameworks, as well as seamless integration with other open source projects. The following diagram depicts these main components and where Apache Liminal comes in:
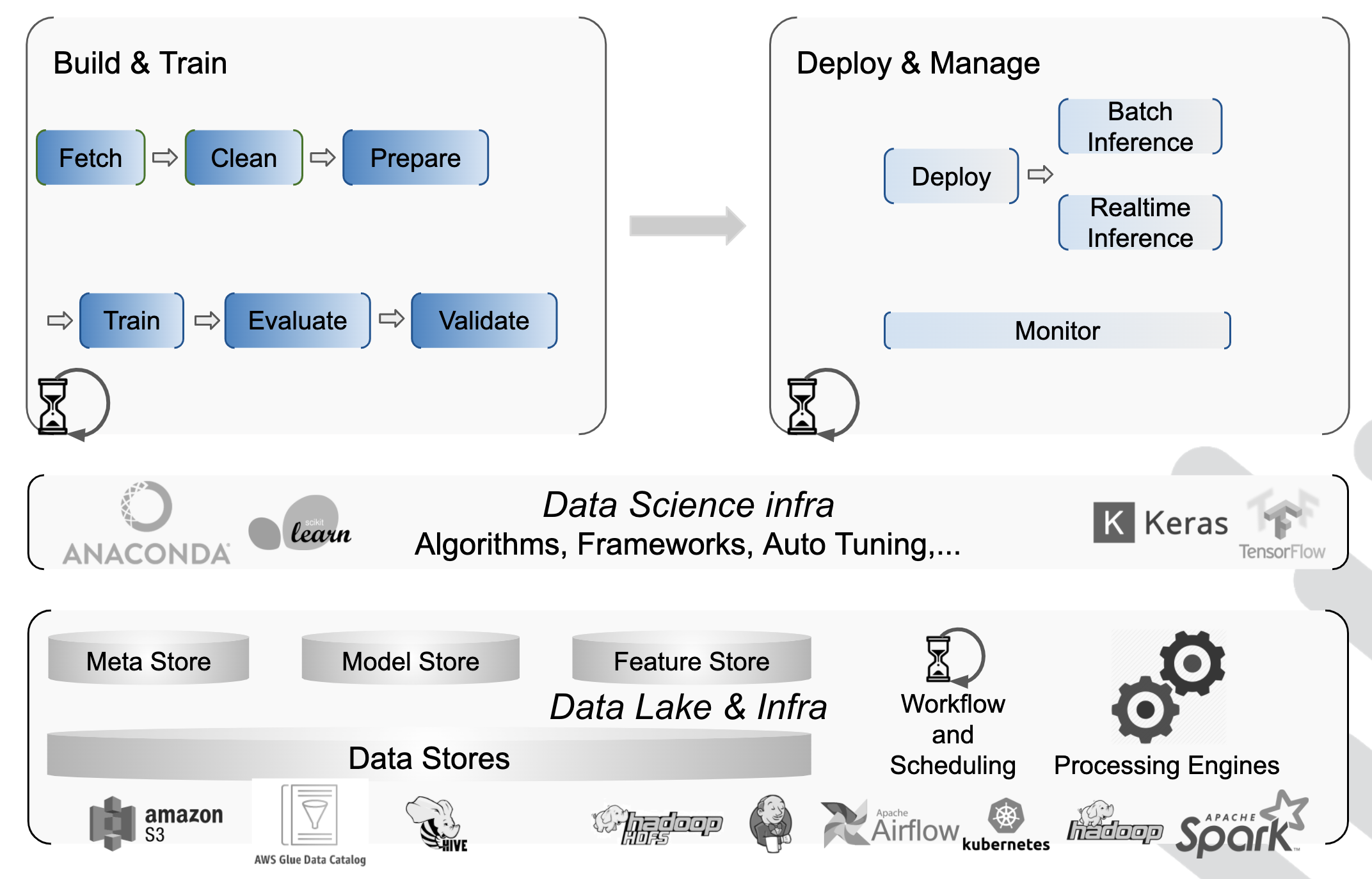
A classical data scientist workflow includes some base phases: Train, Deploy and Consume.
The Train phase includes the following tasks:
- Fetch - get the data needed to build a model - usually using SQL
- Clean - make sure the data is useful for building the model
- Prepare - extract features from the data
- Train - build the model and tune it
- Evaluate - test model integrity
- Validate - test model quality
The Deploy phase includes these tasks:
- Deploy - make it available for usage in production
- Inference - The actual use of the models created by applications and ETLs, usually through APIs to the batch or real-time inference that usually rely on Model and Feature stores.
- Monitor - consistent monitoring of ML models performance and KPIs
Liminal provides its users a declarative composition capabilities to materialize these steps in a robust way, using standard ML/AI frameworks, tools & libraries, e.g. scikit-learn, Pandas, Airfolow, Kubernetes, MLFLow etc. Liminal's plugin architecture provides an easy way to extend and evolve the platform.